

Plusieurs ressources de données supplémentaires développées au SIB ont récemment été reconnues comme cruciales pour la communauté internationale des sciences de la vie. Au niveau européen, SWISS-MODEL et ModelArchive ont été sélectionnés respectivement comme ELIXIR Core Data Resource et ELIXIR Deposition Database. Ces deux ressources sont essentielles pour la recherche en biologie structurelle et ont été développées par le SIB Group de Torsten Schwede à l'Université de Bâle. À cette occasion, nous avons demandé au chef d'équipe du développement logiciel du groupe, Gerardo Tauriello, de nous éclairer sur la manière dont ces ressources ont été développées et sont parvenues à leur succès.
Les protéines sont essentielles à une multitude de fonctions chez tous les êtres vivants : elles agissent comme enzymes pour faciliter la digestion ou dégrader les polluants, comme messagers chimiques dans le système immunitaire ou comme hormones. Leur fonction est étroitement liée à leur structure tridimensionnelle, que SWISS-MODEL et ModelArchive aident les scientifiques à étudier.
Pouvez-vous décrire brièvement SWISS-MODEL et ModelArchive ?
SWISS-MODEL vise à rendre la modélisation des protéines accessible à tous les chercheurs en sciences de la vie dans le monde entier. Son référentiel contient des structures protéiques régulièrement mises à jour, générées à partir du pipeline automatisé de SWISS-MODEL, et donne accès à des structures expérimentales issues de la Protein Data Bank (PDB) et à des modèles computationnels d'AlphaFold et ModelArchive. ModelArchive sert en effet de référentiel dans lequel peuvent être déposées des structures moléculaires déterminées par calcul. Cela comprend des modèles de protéines ainsi que d'ARN, d'ADN, de glucides et de petites molécules apparentées.
En savoir plus sur les logiciels libres et les bases de données développés au SIB
À quel défi ou à quelles questions de recherche peuvent-ils contribuer à répondre ?
SWISS-MODEL et ModelArchive constituent des sources précieuses de structures protéiques déterminées par calcul, en particulier lorsque les structures déterminées expérimentalement font défaut. Cela peut être utile, par exemple, dans la découverte de médicaments ou pour révéler les effets des variations dans les séquences protéiques, car ces deux éléments sont étroitement liés à leur conformation 3D.
De plus, comme SWISS-MODEL utilise des structures connues de protéines similaires comme guides pour prédire les structures des protéines, il peut fournir des modèles dans des configurations 3D spécifiques, ce qui facilite l'étude de la fonction des protéines et de leur interaction avec d'autres molécules. Il complète ainsi avantageusement les méthodes récentes basées sur le Deep Learning et offre des avantages distincts.
Avez-vous un exemple particulièrement intéressant d'application des ressources ?
Dans un cas récent, des modèles générés avec SWISS-MODEL ont été utilisés pour étudier expérimentalement deux anticorps trouvés chez des survivants humains du virus Ebola comme traitement potentiel. Dans un autre exemple, des structures extraites du référentiel SWISS-MODEL ont été utilisées pour prédire par calcul quelles variantes de protéines peuvent causer des maladies.
Des travaux récents qui ont généré des structures computationnelles de protéines dans des cellules eucaryotes qui s'assemblent pour former des complexes ont été déposés dans ModelArchive afin d'être largement accessibles à la communauté. Dans ce cas, les complexes ont permis de mieux comprendre la fonction biologique des protéines impliquées dans divers processus biologiques clés, de la réparation de l'ADN à la division cellulaire en passant par le métabolisme.
Comment ces ressources sont-elles arrivées là où elles sont aujourd'hui ?
Ces deux ressources ont une longue histoire qui a conduit à leur récente reconnaissance au niveau européen. SWISS-MODEL a été lancé il y a 30 ans et, grâce à sa conception conviviale et à ses algorithmes efficaces, il est aujourd'hui l'un des systèmes de modélisation de protéines en ligne les plus utilisés dans le monde pour la recherche et l'enseignement.
ModelArchive a été créé il y a 10 ans, et depuis lors, les modèles in silico de haute qualité sont de plus en plus disponibles, notamment grâce à des méthodes basées sur l'intelligence artificielle telles qu'AlphaFold, lancée en 2021. Cette évolution, combinée à l'élaboration de lignes directrices pour le stockage des structures prédites, a entraîné une croissance substantielle de ModelArchive, qui contient désormais plus d'un demi-million de modèles.
Qu'est-ce qui, dans le fait d'être au SIB, a favorisé leur réussite ?
Le soutien du SIB est crucial pour la stabilité et la fiabilité à long terme de ces ressources ouvertes. Le SIB nous offre la possibilité d'employer du personnel hautement qualifié et expérimenté dans le cadre de contrats à long terme, ce qui nous permet d'accroître les connaissances techniques que nous pouvons conserver au sein de notre groupe. Le fait d'être inclus dans les ressources du SIB a valu à SWISS-MODEL et ModelArchive un haut niveau de confiance, qui se reflète dans leur utilisation, leur impact au sein de la communauté des sciences de la vie et cette récente reconnaissance européenne par ELIXIR. Faire partie du réseau suisse du SIB facilite également la collaboration avec d'autres groupes du SIB, ce qui est extrêmement utile pour tirer parti de l'étendue des connaissances disponibles dans la communauté. Ces facteurs ont également contribué à l'octroi d'une subvention à ModelArchive pour étendreles principes de la recherche ouverte.
Reference(s)
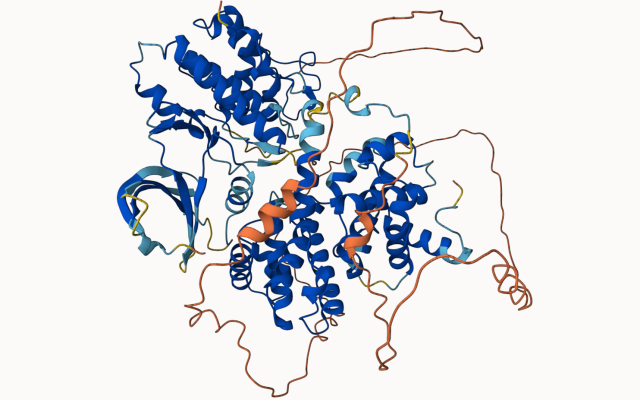
Image de bannière : structure d'un complexe protéique stockée dans ModelArchive à partir d'une étude récente








